PACELC Theorem
Understand the PACELC theorem and its implications for distributed systems.
1. Introduction: Beyond CAP
While the CAP theorem is fundamental, it primarily focuses on how a system behaves during a network Partition (forcing a choice between Availability and Consistency). However, systems spend most of their time operating without partitions. How do they behave then? What trade-offs exist during normal operation?
This is where the PACELC theorem, proposed by Daniel J. Abadi in 2010, comes in. It acknowledges the CAP trade-off but adds another crucial dimension related to performance when the network is healthy.
2. What is the PACELC Theorem?
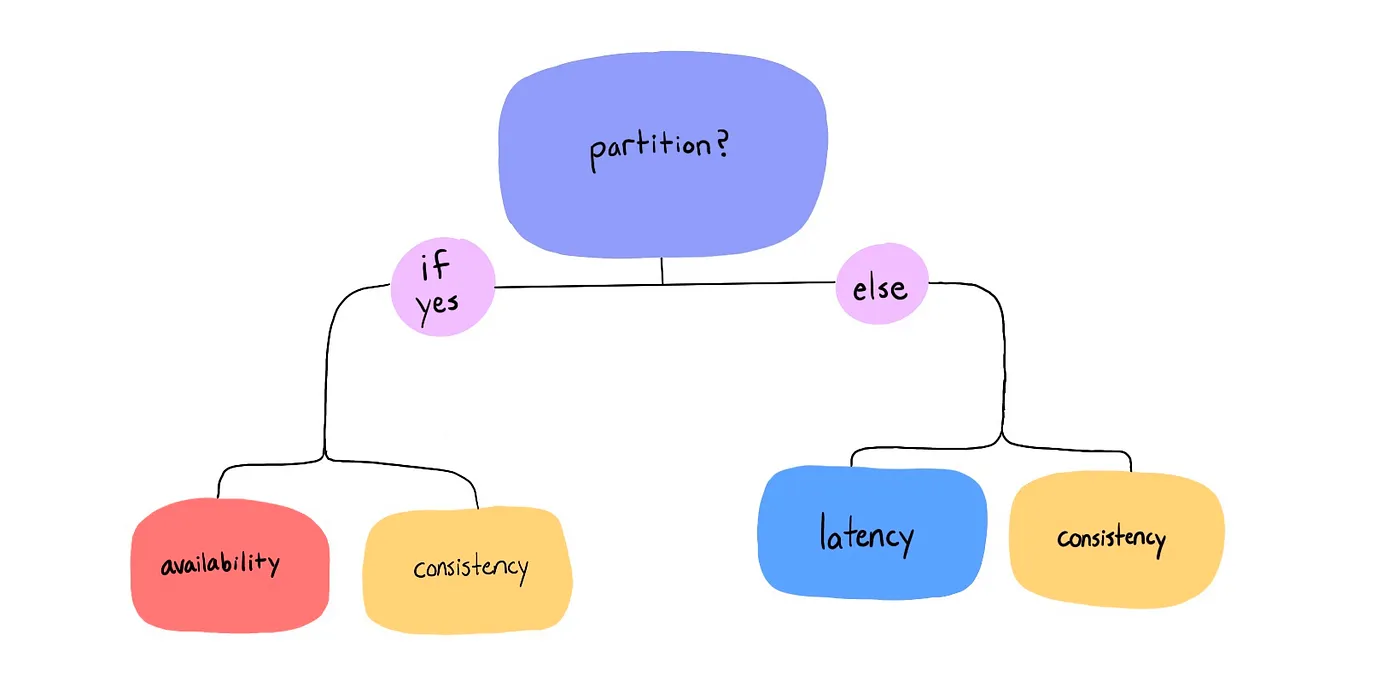
The PACELC theorem states:
For a distributed system, if there is a Partition, then one must choose between Availability and Consistency (the CAP part), else (when the system is running normally in the absence of partitions), one must choose between Latency and Consistency.
 The PACELC Theorem
The PACELC Theorem
Breaking Down the Components
- P (Partition): Network failures prevent communication between some nodes in the system. (Same as CAP).
- A (Availability): Every request receives a non-error response, potentially with stale data. (Same as CAP).
- C (Consistency - First C): All nodes see the same data at the same time (strong consistency/linearizability). (Same as CAP).
- E (Else): Refers to the state of normal operation when there are no network partitions.
- L (Latency):
- Definition: The time delay for an operation (like a read or write) to complete and return a response to the client. Low latency means fast responses.
- Analogy: If CAP’s Availability is about whether the customer service agent picks up the phone, Latency is about how long you’re kept on hold before they give you the answer.
- C (Consistency - Second C): The same definition of Consistency (typically strong consistency) as used in the CAP part. The trade-off here is whether to prioritize maintaining this strong consistency even during normal operation, potentially at the cost of higher latency.
3. The Two Trade-offs Explained
PACELC highlights two distinct operational scenarios and their respective trade-offs:
Scenario 1: Partition Occurs (P) ⇒ Choose A or C
This is exactly the CAP theorem trade-off. When nodes cannot communicate:
- Choose A: Stay available, respond quickly, possibly with stale data (AP System under partition).
- Choose C: Ensure data consistency, possibly by becoming unavailable or returning errors (CP System under partition).
Scenario 2: No Partition / Normal Operation (E) ⇒ Choose L or C
This is the core addition of PACELC. Even when all nodes can communicate perfectly:
- Choose L (Low Latency): The system prioritizes responding quickly. It might read from a local replica or acknowledge writes faster, potentially sacrificing immediate strong consistency for speed (EL System during normal operation).
- Choose C (Strong Consistency): The system prioritizes ensuring all clients see the most up-to-date data. It performs the necessary coordination, even if it increases the response time (latency) (EC System during normal operation).
4. System Classifications under PACELC
PACELC allows for a more nuanced classification of distributed systems by combining the choices made in both scenarios:
PA/EL Systems: (Prioritize Availability if Partitioned / Prioritize Latency Else)
- Behavior: These systems aim to be always available and always fast. They sacrifice strong consistency during partitions (A over C) and during normal operation (L over C). They typically offer eventual consistency.
- Examples: Amazon DynamoDB, Apache Cassandra (default settings), Riak KV, Couchbase.
PC/EC Systems: (Prioritize Consistency if Partitioned / Prioritize Consistency Else)
- Behavior: These systems prioritize strong data consistency above all else. They sacrifice availability during partitions (C over A) and accept higher latency during normal operation (C over L) to maintain correctness.
- Examples: PostgreSQL with strict modes, VoltDB, Google’s Spanner, etcd, ZooKeeper.
PA/EC Systems: (Prioritize Availability if Partitioned / Prioritize Consistency Else)
- Behavior: These systems try to maintain strong consistency during normal operation (accepting higher latency) but switch to prioritizing availability (sacrificing consistency) during partitions.
- Examples: PNUTS from Yahoo, or specific database configurations.
PC/EL Systems: (Prioritize Consistency if Partitioned / Prioritize Latency Else)
- Behavior: These systems sacrifice availability during partitions to maintain consistency, but during normal operation, they prioritize low latency, potentially relaxing consistency guarantees.
- Examples: MongoDB (depending on configuration).
5. Why is PACELC Important?
- Completes the Picture: CAP only tells half the story (what happens during failures). PACELC adds the crucial dimension of performance trade-offs during normal operation.
- Latency Matters: For many interactive applications, response time (latency) is a critical factor for user experience and system performance.
- Guides System Choice: PACELC provides a better framework than just CAP when choosing a database or architecture.
- Explains Design Decisions: It clarifies why systems like Cassandra default to lower latency and eventual consistency (PA/EL), while traditional RDBMS clusters often default to stronger consistency (PC/EC).
6. Relationship to CAP
- PACELC includes CAP as its first part (the “P -> A vs C” choice).
- It extends CAP by adding the second part (the “E -> L vs C” choice).
- It acknowledges that the trade-offs are different depending on whether the network is partitioned or not.
7. Conclusion
PACELC provides a more comprehensive framework than CAP for understanding distributed system trade-offs. It reminds us that:
- When Partitions happen, we must choose between Availability and Consistency (CAP).
- Else (during normal operation), we must choose between Latency and Consistency.
By considering both scenarios, PACELC helps architects evaluate systems based on their behavior during both network failures and normal operation, leading to better-informed design decisions that balance correctness, uptime, and performance according to application requirements.